Send modes
| Synchronous | completes when receive has completed | MPI_Ssend |
| Buffered | completes once buffer is full (immediate) | MPI_Bsend |
| Standard | either synchronous or buffered | MPI_Send |
| Ready | always completes (immediate) | MPI_Rsend |
Synchronous: the sending process expects a hand-shake by the receiving process acknowledging receipt of the message. Safest of the send modes. Can be wasteful in time. The sending and receiving nodes are synchronized.
Buffered: The sending node writes to a user defined MPI buffer for temporary storage until the message is sent by MPI. The sending and receiving nodes are NOT synchronized. The analogy is to drop a message in a post office mailbox to be picked up later. The user must define buffer space via calls similar to the C routines malloc and free.
MPI_Buffer_attach( void *buffer, int size )
MPI_Buffer_detach( void *buffer, int *size )
The size must include an overhead of size MPI_BSEND_OVERHEAD. Note also that if many sends must occur in a row the buffer must have a size large enough to store all the messages since nothing guaranty the receive completion while the different messages are sent.
Standard: The standard MPI send is either of synchronous or buffered type. The issue is here the capacity of the network (i.e., the MPI daemons) to store temporarily the message content. Large messages may imply a buffered scenario, whereby MPI will create and free a buffer area large enough to contain the message.
Ready: Dangerous mode in which NO handshaking takes place, MPI assuming that the receive process is ready to receive the message sent by the sending node. This mode is the fastest of course, but should only be used with special precautions.
Syntax:
MPI_Send( void *buffer, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm com )
buffer: message address
count: number of elements in the message
Datatype: one of the MPI datatype
dest: target process to receive the message
tag: a message identification tag
com: the communicator to which both send and receive processes belong
"buffer" refers to the address of any region in memory. An array name (starting address of array), or a single variable (the address of it, &variable ), is what is expected. count elements of type datatype starting at buffer will be sent by the MPI send routine.
Receive modeThere is only one MPI receive mode, MPI_Recv. The routine is blocking, i.e., will block until a message is received. The user may specify a node or a tag value for the expected message or accept any message.
Syntax:
MPI_Recv( void *buffer, int count, MPI_Datatype datatype, int source,
int tag, MPI_Comm com, MPI_Status *status )
buffer, count, datatype, source, tag, and com have the same meaning as in the send routine, except that source specifies the sending process and buffer is the location where the MPI receive routine is to store the incoming information.. status contains information about the message, the communication envelope.
MPI_ANY_SOURCE and MPI_ANY_TAG are used when messages are to be received from any source or with any tag.
The message envelope contains at least:
1. the rank of the receiver process
2. the rank of the sender process
3. the message tag
4. the communicatorunder which the message was sent
The message envelope is constructed by the send routines. A message is therefore the data + an envelope.
MPI can provide information about the size, origin, and tag of any received message through access to the message envelope. The variable status provides this information. The mpi.h file defines the structure of this variable as follows.
/*
Status object. It is the only user-visible MPI data-structure
The "count" field is PRIVATE; use MPI_Get_count to access it.
*/
typedef struct {
int count;
int MPI_SOURCE;
int MPI_TAG;
int MPI_ERROR;
int private_count;
} MPI_Status;
This variable is visible from the user code. For instance, status.MPI_SOURCE tells you the rank of the sending process.
Note that the size of the data, status.count is private. Therefore it can only be obtained via the MPI query routine
MPI_Get_count( MPI_Status *status, MPI_Datatype datatype, int *count)
The number of items received can be less than count in the MPI_Recv call. The latter only specifies the maximum size of the receiving buffer.
It is recommended that the synchronous send routine, MPI_Ssend, be used to send messages. The advantage of using this routine is that it does not depend on the MPI buffer or on pre-synchronization of the sending and receiving processes.
A danger in writing a parallel code is to create a deadlock in the communication channels, whereby the nodes are blocked from going to the next statement in the code upon a MPI_Ssend, the receiving node also being blocked from a MPI_Recv statement - itself being blocked in the MPI_Ssend statement.
ith process: MPI_Ssend(
...,j,...);
MPI_Recv( ...,j,...);
jth process: MPI_Ssend(...,i,...);
MPI_Recv(...,i,...);
A regular MPI_Send() will solve this problem. But, the safe way to handle this problem is to use a Red-Black or Odd-Even scheme, whereby the order of send/receive is inverted for the odd-even processes. Schematically:
even processes:
MPI_Ssend( ...); <- sends to odd processes
MPI_Recv( ...);
odd processes: MPI_Recv(...);
<- receives from even processes
MPI_Ssend(...);
The use of the non-blocking send and receive routines might allow better efficiency (codes computing during communication time) but presents other dangers that will mentioned later.
double MPI_Wtime()
returns a double precision number giving the clock time in seconds since some arbitrary time origin in the past. This origin is guaranteed not to change during the lifetime of a process. So calling MPI_Wtime twice and subtracting the results gives the elapsed time between the calls.
double time1, time2,
elapsed_time
time1 = MPI_Wtime();
...
time2 = MPI_Wtime();
elapsed_time= time2 - time1;
Communication is significantly more expensive than calculations. The cost of communication comes from the two major phases in sending a message: The start-up phase, and the data transmission phase. The total time to send K units of data for a given system can be written as
t total = t s + K t c
t s is sometimes referred as the latency time; it is the time to perform hand-shake protocol to start a point to point communication. t c is the time to transmit units of information; the reciprocal of t c is the bandwidth. The latency time can be as high as 500 microseconds for TCP/IP and as low few microseconds on a CRAY T3E. The bandwidth of our CYBORG system (fast-ethernet) is peaked at 100 MB/sec ( real speed might be ~50MB/sec).
You can measure these communication costs via simple codes that time the send/receive messages. The program ping_pong.c (see the Edinburgh notes) does precisely this via the MPI_Wtime() routines. It sends messages of various length back and forth between two processes and measures the round trip times. Running this program produces the following figures.
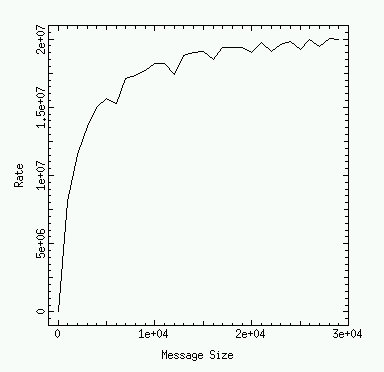
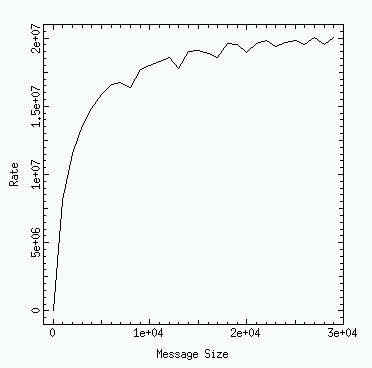
The effective bandwidth (transmission rate) is plotted versus the length of the messages. Small messages are costly because of the start-up cost and produce a low effective bandwidth. The latency becomes insignificant for large messages and the effective bandwidth saturates into the network bandwidth.
Read the code, understand it, and run it to reproduce the figures above.