The Monte Carlo technique to perform integrals applies best to higher dimensional integrals for which other traditional methods become difficult. For instance, using few hundred points to perform a 1-D integral using the trapezoidal or Simpson method is easily done. However, the same in multi-dimension does not apply: a five dimensional integral
![]()
would require 2005 function evaluations to implement a method with
200 points per axis.
Statistical Physics requires integrals of much higher dimensions, often of the
order of the number of particles.
The Monte Carlo approach deals with this problem by sampling the integrand via statistical means. The method calls for a random walk, or a guided random walk, in phase space during which the integrand is evaluated at each step and averaged over.
This problem is presented here as a challenging case to implement via a parallel algorithm. Different implementations will require us to use all the MPI functions we have seen so far. In the following, the Monte Carlo method will first be explained, then it will be implemented serially, and then the Metropolis algorithm will be explained, and implemented serially and in parallel.
The Monte Carlo Method is best explained via a 1-D integral
![]()
Rewrite
I = (b-a) < f(x) >
where <f(x)> is the average of f(x) over the interval (a,b).
![]()
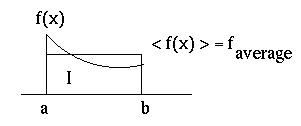
The error in evaluating <f> is described by the variance
![]()
The method is illustrated by integrating f(x,y)=1 in a circle, namely
![]()
This corresponds to
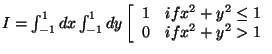
The Monte Carlo approach is implemented by enclosing the
circle in a square of side 2 and using random numbers in the interval
x = (-1,1)
and y = (-1,1). The area of the circle is π 12 and
the area of the square is 22. The ratio of these areas is then π/4.
Random numbers, taken as x - y coordinates of points in a plane evidently fill in the plane uniformly. Therefore, the numbers of random numbers that fall within the circle and the square are proportional to their areas. Therefore
π = 4 # hits in circle / # random numbers
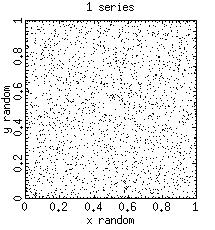
The program random_demo.c generates x and y coordinates in the interval (0,1) via calls to RAND( ), the build-in pseudo random-number generator function in the "C" compiler. The code is serial and can run on any computer.
random_demo 2000 > data_file
runs the random_demo to produce 2000 random points which are piped in a file data_file. The latter can be plotted using gnuplot. It produces the following graph.
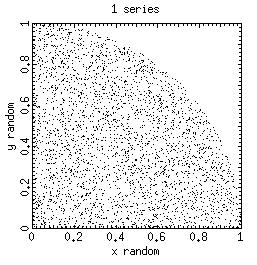
The program monte_pi_serial.c
calculates π by the Monte-Carlo method. It
uses random numbers in the interval [0,1].
The error in calculating π follows from the standard deviation calculation in the following way:
![]()
![]()
![]()
![]()
The random sampling of a function clearly works best if the function is a constant. (Why don't you then get the exact value of π in the example above?) If the function varies rapidly, or is locally peaked, the Monte Carlo method will not converge as rapidly. What is required is a "guidance" of the random sampling that emphasizes sampling where the function is large or varies rapidly. Let's illustrate the concept in 1-D.
![]()
Introduce a weight function w(x)
![]()
where w(x) is required to satisfy
![]()
Change variable to y
![]()
such that
dy = w(x) dx, y(0) = 0, and y(1) = 1.
![]()
The weight function w(x) is chosen such that
[f/w] is aproproximately constant.
The Monte Carlo sampling of [f/w] with
uniform random sampling in y variable will then be accurate.
![]()
Koonin and Meridith (Computational Physics, 1989) give the example
![]()
with
![]()
In this simple case, the inversion x(y) is possible analytically.
![]()
x = 2 - (4 -3 y )
In general, this inversion x(y) is difficult or impossible to perform analytically. An alternate approach must be used.
The relation dy = w(x) dx implies another interpretation of the method. Random numbers uniformly distributed in y will be distributed according to w(x) in x. Therefore, the guiding action of w(x) can be achieved by generating random numbers according the the probability profile w(x). This holds in phase spaces of arbitrary dimension. The problem translates into that of finding random distribution of arbitrary probability distributions.
Uniform random numbers in interval (0,1) have an average value of 0.5. A binning in intervals dx will show an average number of random number
number / bin = total # of random numbers / number of bins.
The number of random numbers in the bins will fluctuate around the average with a Gaussian distribution.
Random numbers distributed according to the distribution w(x) will bin according to w(x).
The Metropolis algorithm generates a random walk guided by the weight function w(x). The algorithm in 2-D involves the following steps. Starting from a point (xi, yi).
Koonin and Mederith (Computational Physics, 1989) provide a simple proof that the algorithm produces the desired random number distribution w(x).
The step η in the Metropolis algorithm is arbitrary. If chosen small, the acceptance ratio will be high (a point in the neighborhood of an acceptable point will also likely be acceptable). But overall coverage of the phase space will be very slow. If η is large, the phase space will be efficiently covered, but a new point will seldom be accepted by the Metropolis criteria. In either case ineficiency follows. An empirical rule is to choose η such as to have an acceptance ratio about 0.5 - 0.6.
A concern about the algorithm is that the random numbers generated by the Metropolis algorithm are correlated. A way to guard against this (Koonin and Mederith , Computational Physics, 1989) is to calculate the correlation functions
![]()
and select each kth random number generated by
the algorithm with k selected to produce a small value of Ck.
Lets consider the integral
![]()
The integral is peaked (torus shape) around the origin.
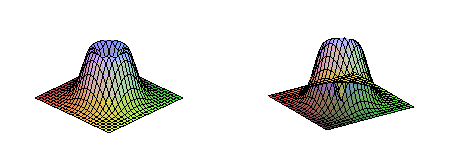
The Gaussian function
![]()
can be chosen to guide the random number selection.
The program Metropolis_Gaussian_Demo.c illustrates a random numbers generation according to w(x,y). Note that arbitrary values for the step size (η=0.2) and k (k=1) were chosen; no effort was made to chose them optimally.
This code, with 2000 points, produced the following random number distribution.
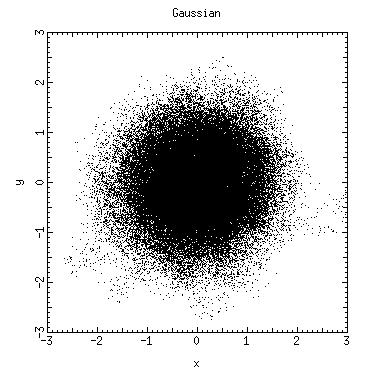
The program Metropolis_Gaussian_Integral.c
performs the integral.
Metropolis_Gaussian_Integral -p > data_file
or
Metropolis_Gaussian_Integral
This code prompts the user for more points to be added to the Monte Carlo integral. The calculation of the error may show the calculation not to be accurate given that the choices of η and k were not optimized.
Pseudo random numbers are often generated by a linear
congruent algorithm. The integer
random number xi+1 is generated from the previous one by
xi+1 = ( xi
a + b ) mod c
The coefficients a, b and c are chosen to generate
statistically good random numbers in a specific integer range (Numerical
Recipes). Often the random numbers
are generated using different linear congruence relation, and mixed via random
selection as in RAND1 and RAND2 (Numerical Recipes).
The procedure to generate random numbers is deterministic. Two different nodes on a parallel machine will produce exactly the same sequence if "seeded" in the same way. The question then arises as to how to generate "good" random numbers on the different nodes of the parallel computer that will remain meaningful when used as a single set.
One solution is to generate sequences on each node based on different seeds. The code random.demo_2_series.c simulates this approach by generating 1 or 2 sequences of random numbers that can be analyzed for their goodness. The idea is to look for the goodness of a sequence in which the first and second half of the series are generated with different seed versus sequences generated from a single seed.
random_demo_2_series 2 1000 > data_file
The following filters can be used to acquire some feelings for the goodness of these random numbers
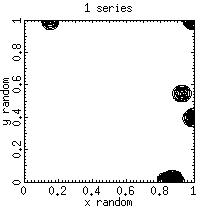
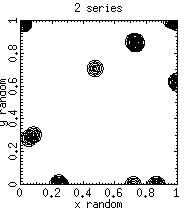
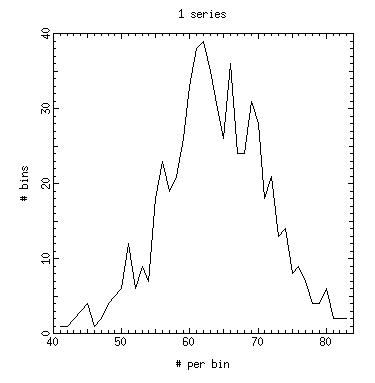
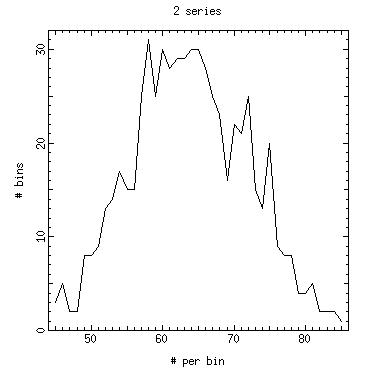
Clearly the random numbers sequences generated from sequences using different seeds have different properties than sequences generated from single seed.
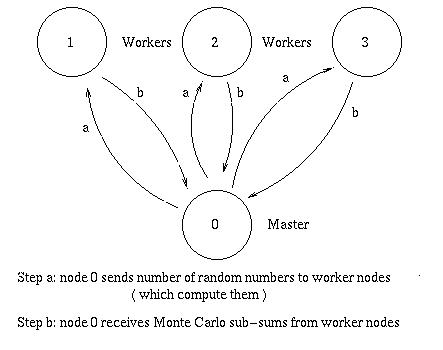
We use here the approach that Random numbers should be generated on one node and distributed to the nodes which need them. This avoids the use of sequences generated from different seeds. Realistic applications often require time-consuming function evaluations. Therefore the inefficiency inherent in our approach is dwarfed by the large function evaluation times. This is also the approach used by Gropp et al. in "Using MPI".
A parallel implementation of the Monte Carlo integration must have the random sequence distributed to the different nodes, either by communication or by a local generation of the sequence. We implement here three versions of the code.
This code generates the random numbers on nodes 0 and passes them onto the worker nodes. The latter compute the Monte Carlo sub-sums and pass these sub-sums to node 0 which finishes the sums. The MPI_Reduce() function can be used to expedite the global sums
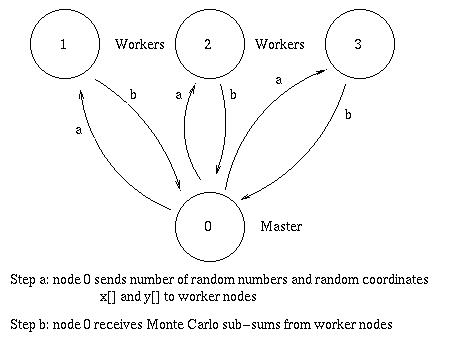
Metropolis_Gaussian_Parallel.c implements this approach.
This code implements the concept of a random number server; this is a node reserved to serve random numbers with weight w(x,y) to whichever node requests it. The code sets node 0 as a master node to direct the calculation and interface with the user. Node (numprocs-1) is the random numbers server, and nodes 1 to (numprocs-2) are the worker nodes which complete the Monte Carlo sub-sums.
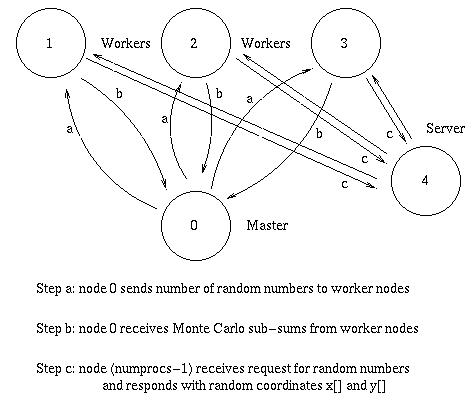
Gropp et al, in "Using MPI" implements this version of a Monte Carlo integration to calculate π.
In this version, node 0 administers the ranges of random numbers to be generated for each workers, but leaves the actual generation of the random numbers to the nodes themselves. Upon receiving a range, i.e., random numbers range 1001 to 2000, the worker nodes generate these numbers and calculate the Monte Carlo sub-sums. This implies that they must generate and discard those random numbers prior to their range selection. This is a waste of computing cycles, but given the speed of computing versus the network speed it maybe the most efficient approach after all.
The scheme is therefore