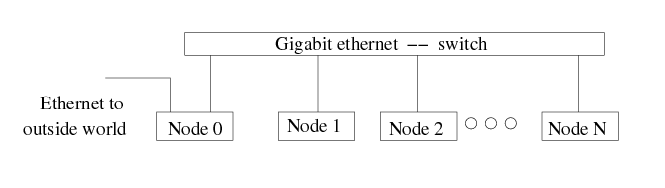
Commercial parallel servers do not differ much from this abstract architecture that we just described. Servers by Dell, IBM, HP, ... may look very different but are conceptually very similar. The nodes often come in rack-mounded units of 1U or 2U heights. This provides for efficient use of floor space and efficient cooling. Another subtlety might be that the units come internally with multiple CPUs or multiple core chips which behave like multi-CPU units.
The hardware model that a MIMD computer exhibits is therefore a series of nodes which are complete computers by themselves with a CPU unit, memory, local disks space, and the mean for that to be integrated via the bus. Software-wise, each of those nodes has its own Operating Systems (OS), which in our case will be a Linux implementation of some sort.
A software environment must reside in the nodes on top of the local Operating System for the users to submit tasks in parallel. This software environment will have two very important functions: the administration of the sub-tasks and the facilitation of task-to-task communication. The sub-tasks to be executed must be submitted to a subset of the nodes of the parallel system, monitored, handled appropriately when they misbehave, and terminated when done. The software should also provide the means for the sub-tasks to communicate among themselves since the latter are part of a global task.
Parallel Virtual Machine (PVM)
Developed at Oak-Ridge National Laboratory. Public domain software. Runs on most parallel systems. C- and Fortran-binding library of routines to spawn processes, administer processes, and facilitate message passing between processes.
Message-Passing Interface (MPI)
Developed at Argonne National Laboratory. Public domain software. Runs on most parallel systems. C- , C++- and Fortran-binding library of routines administer processes, and facilitate message passing between processes. Launching tasks is performed from within the MPI run-time environment.
The MPI approach to message passing seems to have become the de-facto standard among the builders parallel machines. This course will use the modern version of this standard.
Message-Passing Interface 3 MPI3
The current MPI standard, MPI3, differs from the original standard in a few aspects. First, it clearly separates the administration of the modes from that of the computing tasks. Second, it implements new parallel I/O capabilities as well as one-sided communication. It also supports two way communication.In this course we are going to use the implementation MPICH 3.0 " of the MPI3 standard developed at Argonne National Laboratory.
The MPI3 Software Model is that of a large demanding computing task which is divided in sub-tasks running under the umbrella of the MPI3 system. The MPI3 serves to support the communication between the sub-tasks as well as the overall administration and monitoring of the sub-tasks themselves. Therefore, the first action of MPI3 is to establish a virtual machine, a communication ring, within a subset (or all) of the physical nodes of the parallel computer. Then, MPI3 distributes the parallel jobs among the nodes and establishes communication handles within that virtual computer to handle the communication needs of the individual sub-tasks.
The MPI3 standard establishes a clear distinction between the administrative tasks of establishing and maintaining the communication ring and the administration of the parallel jobs, very much like in the PVM standard. This is made evident by having an independent software suite, the Hydra Process Monitor, which handles the virtual machine establishment and administration.
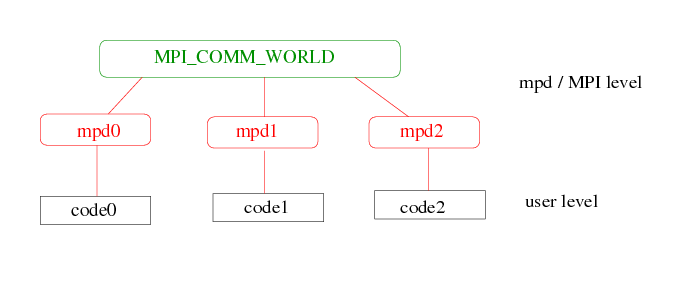
From a practical point of view, a single and simple statement is suficiant for the user to establish an MPI3 communication umbrella and submit parallel tasks. For instance
mpiexec -N 6 ./fun
will start the MPI3 communication umbrella on your local machine, then deploy 6 instances of your code fun and monitor their execution. The code fun needs to be an executable and be specified with an explicit location ( . / fun ) as required by the UBUNTU OS for security reason.
The
For instance, let us submit the following very simple shell-script called test-script:
echo "----------------------- Michel was here..." date echo $user hostname pwd echo "------" ls echo "----------------------"This script does not need compilation since it is written in simple shell commands. Make it executable via chmod +x test-script .
Now, submit 6 copies of the script on your station via:
mpiexec -N 6 ./test-script
Next, submit the script on two particular stations of your choice in 12-704 via:
mpiexec -host xphy11.physics.xterm.net 3 -host xphy12.physics.xterm.net: 3 -N 6 ./test-script
It is obviously cumbersome to explictly type the host names in mpiexec. To avoid this, a list of available host names can be incorporated in a file, hosts_list (arbitrary name), with the following syntax:
xphy10.physics.xterm.net:1 xphy11.physics.xterm.net:1 xphy12.physics.xterm.net:1 xphy13.physics.xterm.net:1 xphy14.physics.xterm.net:1 xphy15.physics.xterm.net:1
The submission of the script could be
mpiexec -f hosts_list -n 6 ./test-scriptThis will run test-script on 6 stations, 1 task per station.
The hosts in hosts_list are listed one node per line following the syntax:
host-name : no-of-processor
where host-name stands for any allowed hosts on which to launch the tasks and no-of-processor is the maximum number of processes on each node. Normally, the number of tasks should be limited by the number of CPUs or the number of cores in each node.
The names of the hosts can be simplified as long as the hostnames can be resolved. Likewise, the number of processors ( :1 ) can be omitted since all the hosts (in 12-704) are homogeneous, at one processor; this yields
xphy10 xphy11 xphy12 xphy13 xphy14 xphy15
The MPI3 standard allows communication in between tasks by various means. The default is via Unix sockets which imply the capability of communicating over Ethernet. Communications can also proceed via shared memory channels. For instance, emory channels could be used betwen tasks residing in the same physical node.
No matter what mpiexec elects to implement in terms of communication, it is safe to assume that the user's directory should be visible and readable by the tasks in the entire virtual machine. Short of this, the diverse tasks will all require you to type passwords again and again.
The MPI daemons (unless otherwise specified) work through ssh. It is convenient to install a ssh key on the hosts to avoid ssh to require a passwd when invoked.
It is important to know whether the physical parallel computer is homogeneous (all nodes are alike) or inhomogeneous (the cluster could be a hodge-podge of computers). This brings about the fact that the communication channels that MPI3 opens up between the different nodes might need to translate from one data representation to another if the cluster is inhomogeneous. The MPICH3 implementation supports the Linux and the Windows Operating Systems. The Linux environment is the most tested and supported environment.Another issue derives from the possibility that the nodes on the parallel cluster might be multi-CPU nodes. In such a case, multi tasks can be loaded on each node for better efficiency with the Operating System left to administer those tasks locally. This must be specified in setting-up the MPD daemons, one per node, while more than one tasks be allowed to exist. The tasks on the same node could communicate via shared memory instead of Unix sockets. This will also influence the way that the tasks are going to be loaded on the system. For instance, if six tasks need to be loaded on a four nodes system, the tasks are going to be loaded in a round-about way, namely task 0 will be on node A, 1 on B, 2 on C, 3 on D, 4 on A and 5 on B by default. On the other hand, if two CPUs exist on each node it might be advantageous to load tasks 0 and 1 on A, 2 and 3 on B and 4 and 5 on C.
Consideration needs to be given as well for the existence of dual and quad core CPU chips which may populate the node of the parallel cluster. These chips are equivalent to have two or four CPU independently working in a single node. Therefore the MPD commands ought to be warned that there are equivalently multi-CPUs on each node.
Finally MPICH3 allows the use of different daemon handler in the administration of the parallel system. MPI by itself stands for one such administration tool, the default of the system. There exist two other administration systems, the SMPD which is used mostly by Windows machine and the GFORKER system which is used for developing new concepts within MPICH3 itself.